Project: Crosslingual Character / Syllable Relationships
 As with Romance languages and Latin, many Asian languages share vocabulary through Chinese, but it’s less obvious. I’m thus making a reference table to make them clear and discoverable for learners of more than one Asian language. Help needed! If you’d like to, please contact me! Linguistic knowledge not required.
As with Romance languages and Latin, many Asian languages share vocabulary through Chinese, but it’s less obvious. I’m thus making a reference table to make them clear and discoverable for learners of more than one Asian language. Help needed! If you’d like to, please contact me! Linguistic knowledge not required.
Why Do We Need This Reference?
“Difficult” is a relative term: Spanish, French, and German are considered “easy” languages for English-speakers due to similarities in grammar, vocabulary, and writing, while Korean has practically no relation to English and so may be seen as “difficult.” Neither Japanese, Korean, Chinese, nor Vietnamese share a language family with each other (practically), but they have all seen Chinese influence, creating some common vocabulary between them all, just like how those European languages share Latin roots and words. I would thus argue that once you learn one of these languages, the other languages lose their place as “difficult” since the shared vocabulary (along with grammatical concepts) will serve as a nice springboard toward learning the other.
From my experience and what I’ve seen, this means there are connections you can take advantage of between most Chinese languages, Hokkien languages, Korean, Japanese, Vietnamese, and maybe others to lesser extents (such as through loanwords in Indonesian). However, compared to, say, Romance Languages, these connections may be less obvious due to more drastic differences in pronunciation and writing systems, so I believe we need extra effort.

A Table for Comparing and Contrasting
Despite the pronunciation changes, since Chinese languages are made up of a very small set of syllables attributed to various characters, I believe it’s realistic to make a table of all the syllables and include what they sound like in various languages. This will probably be more efficient as a sort of database, but for now, it’s easier to build it as a spreadsheet.
So here’s a sample below. Attempting a neutral option, I placed the Chinese character in the 1st column, and the other columns hold pronunciations of applicable languages. Currently, they are Mandarin, Japanese, Korean, Cantonese, Shanghainese, Southern Min, and Vietnamese. What could we learn from this?
Look at the very first entry and see what you discover. It is the character 学 or 學, which relates to learning. If you can’t read them , the Japanese reading is “gaku” and the Korean one is “hak.” FYI, readings marked with a question mark are ones that I have not confirmed yet, and yes, I know the Mandarin tones are redundant – it’s on purpose. Full disclaimers at the end.
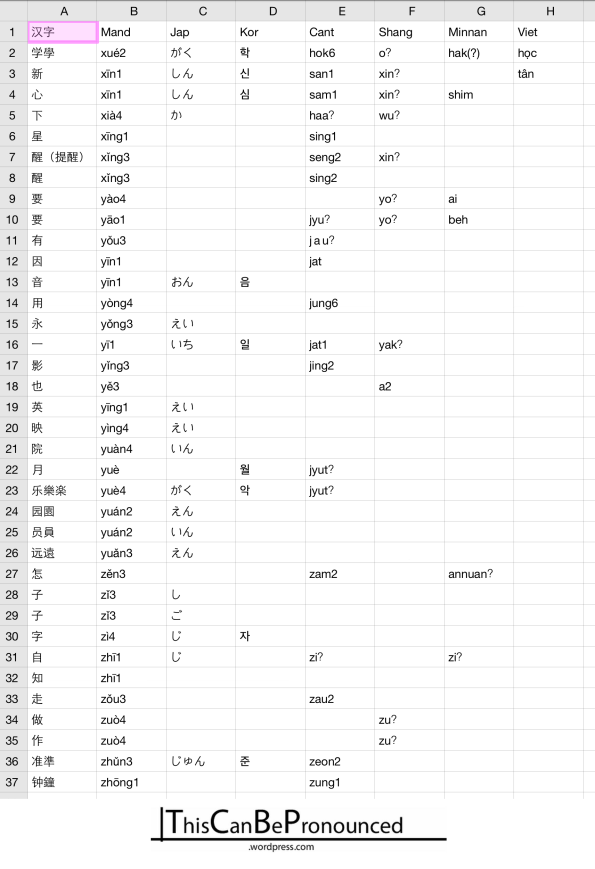
Notice anything? Most of them start with an h, have “a” or “o” as a vowel, and end with a closure, which Japanese tends to bounce into a full syllable. Interestingly, we see that Mandarin is the bizarre language in this case; even amidst three other Chinese languages (Cantonese, Southern Min, and Shanghainese), its pronunciation seems to make no sense. Luckily, in almost every other case I’ve seen, Mandarin pronunciation is also related.
Now, that was only ONE example of a “hak / hok” syllable. I don’t know what happens when we compare more, but building this table will show us these answers. Hopefully, we’ll confirm that any time you see a “hak / hok” syllable, we will see the same pattern across these the languages. However, it’s also possible that “hak / hok” syllables with different meanings have different pronunciations in some languages. After all, I’m sure not all the languages have the exact same number of available syllables.
Cool! But…Am I Supposed to Study This???
NO. NO. NO. This would be for reference only. It’s a way to keep a record so that if you start noticing patterns or choose to learn a few, you can check this. All I’m doing is writing down what many multilinguals find out on their own: as they learn more and more of two related languages and pick up on these patterns, they are more likely to be able to guess how to pronounce a word in the other language. I personally know many people who do this. Basically, this would help for a much more scientific and reliable approach toward trying to change a word you know in one language to use in the other – over 9000% more reliable than tacking O’s after English words to make them Spanish!
What’s Next? Well, I Need Help!
Assistants! Volunteers! Slaves! Beasts of Burden! Camels! Come one, come all!
Other than that, I need to keep collecting this data for more common characters. For example I have “yuan” listed four times, representing four different characters / meanings. In Japanese, two of them become “in” and two become “en.” What about Korean? What about Cantonese?
I could use people to fill in more of these cells. It would be best if you know one of these languages so that you can add them from memory, but I have dictionaries we can use.
If there are some strong trends, then hopefully the table can be simplified and shortened in the future by breaking down full syllables (like “yuan”) into their parts: initials (in this case, y-) and finals (in this case, -uan). I’ve already noticed a few of these trends, which means the table as it is now may be unnecessarily long.
Most immediately important, however, is: Has anyone else partially done this kind of table already? Maybe for only two languages? I’ve been trying to find them. Let me know if you know of any!
If you want to offer any help (even if you’re not sure how you can), please reply, contact me through the Contact TCBP page, or message me through the Facebook page. I’m going to be doing this no matter what, since at the very least I want it for myself, but I’d want to this out there for anyone else who can use it, so I do ask for your help!
Cooperation makes things happen!
One of my favorite songs from way back when!
Notes about the table:
- For now, my table shows a 1-to-1 relation between syllables / characters but I am well aware there are many cases where that’s not true. If I keep a spreadsheet format, I’ll have to have redundant entries or an extra column or something.
- Readings marked with a question mark are ones that I have not confirmed yet – I just know they kind of sound that way or I need to confirm the tone.
- Blanks simply mean I do not know or haven’t filled it in yet.
- If a character happens to not exist in one of those languages for sure, I’ll write N/A or something.
- Mandarin’s pinyin is purposely redundant, having both tone marks and numbers. This makes it easy to strip one or the other if desired.
- The table is ordered alphabetically by Mandarin Pinyin.
- 1st column may hold multiple variants of the same character: first simplified, then traditional, and then any others in the order of the given languages.
- Characters listed twice or more are that way to allow the listing of other existing pronunciations.

any progress on this?
LikeLike
Definitely! It is slowly but continually being updated. I am soon to open it up to a few select people to help me keep populating it. If necessary it may be further opened up later on, like a limited-access wiki or something.
LikeLike
Please note that Korean and Japanese languages are very similar in grammar and in syntax. They differ importantly only in vocabulary, alphabet, and phonetics. Of course, both of them are linguistically distinct from Chinese, [but] heavily influenced [by it] in vocabulary and (for Japanese) in alphabet and writing.
LikeLike